How Can We Help?
How to Teach and Learn Modern AI: Training Models for Machine Learning Through mBlock 5
How to Teach and Learn Modern AI: Training Models for Machine Learning Through mBlock 5
This is a tutorial on understanding and teaching machine learning with mBlock 5.
This page explores how to introduce the knowledge of artificial intelligence (AI) to beginners, such as primary and middle school students, and how to design activities and problems to make learners think and experience AI. “Knowledge point” and “Think about it” are provided on this page as references for teachers to make teaching plans.
This page is licensed under the Creative Commons Attribution 4.0 International license agreement.
The latest version of mBlock, mBlock 5, enables a machine to learn visual models. It is an important tool for experiencing, learning, and creating visual AI applications. On mBlock 5, you can quickly train the learning models of a machine to be used in block-based coding. mBlock 5 can also be used in combination with hardware such as robots to implement various interactions.
Note: The use of machine learning requires a camera and some computer functions. It’s still experimental. Check whether the computer used in the classroom can use this function smoothly before using it to teach a class.
1. Download and install mBlock 5
Open the following page in your browser and select the mBlock 5 version that is applicable to the operating system running on your computer.
https://www.mblock.cc/en-us/download
2. Enable machine learning
Click the Panda sprite to select it.
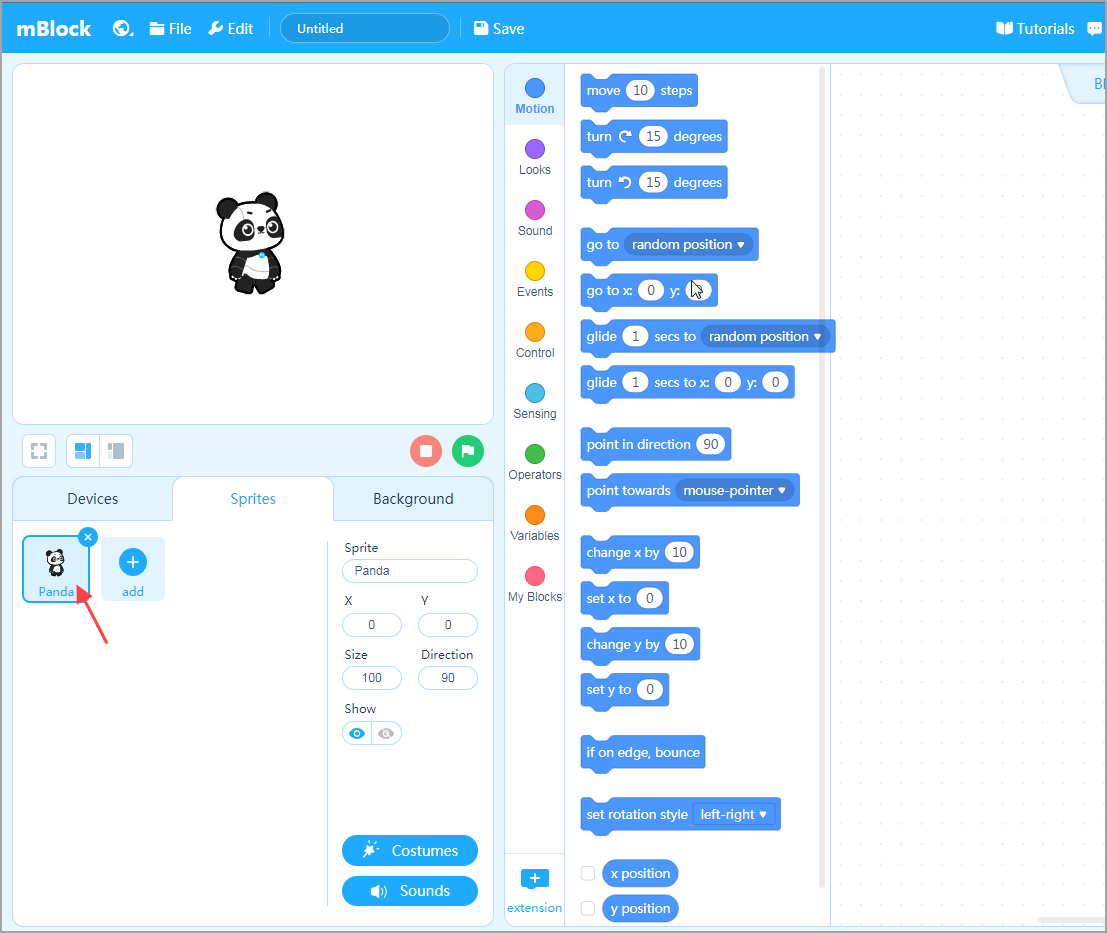
Then, click + extension to enter Extension center.
In Extension center that pops up, click + Add at the bottom of Teachable Machine.
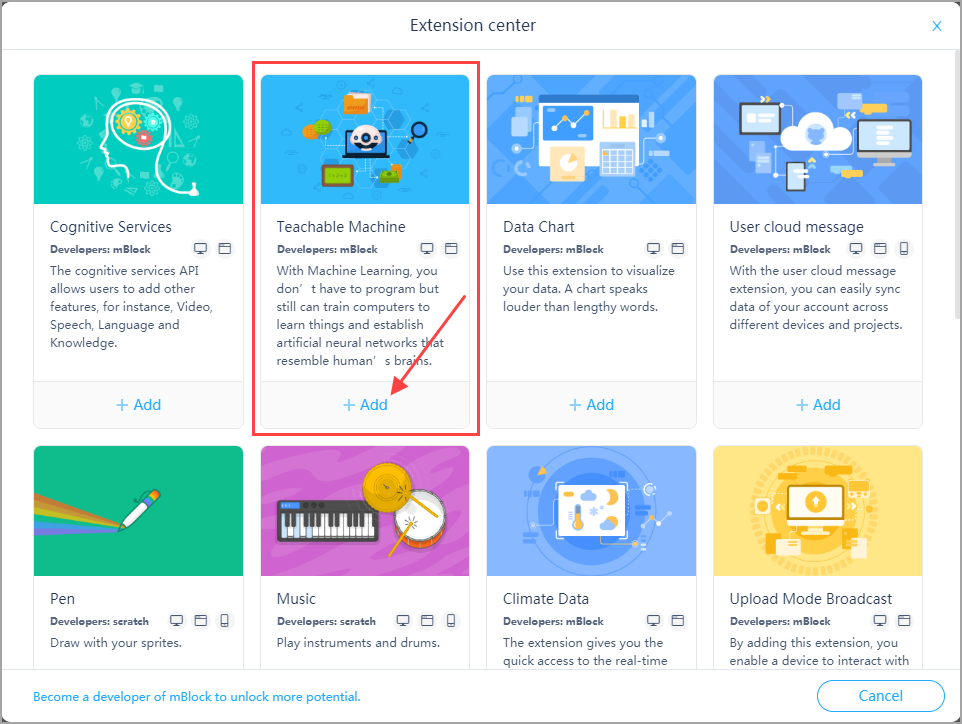
WHY SWITCH TO PANDA? Because on mBlock 5, extensions are sprite-related; an Arduino or MicroPython robot can’t run complicated visual models, and therefore the Teachable Machine extension is not provided for devices. What if you want to use it to control a robot? You can use the communication variables to communicate with the robot. But that’s another topic.
3. Training a machine to learn visual models
Here is an example of how to train a machine to learn visual models in a “rock-paper-scissors” program.
Generally speaking, to use visual models learned by a machine includes three steps, namely training, testing, and application. If you want to create an application that can identify the rock, paper, scissors gestures, first you need to teach the computer what a rock is, what scissors are, and what paper is.
Knowledge point: The models we’re going to build can take an input (say, a picture) and classify the input (for example, “scissors”, “rock”, or “paper”). This model is also called a classifier. Classifiers are very useful in our daily life, for example, they are used in parking lots to record license plate numbers, shooting the license plate numbers with cameras and classify the numbers into the categories of 0 to 9.
After adding the extension, in the new TM category, click Training model to train the model.
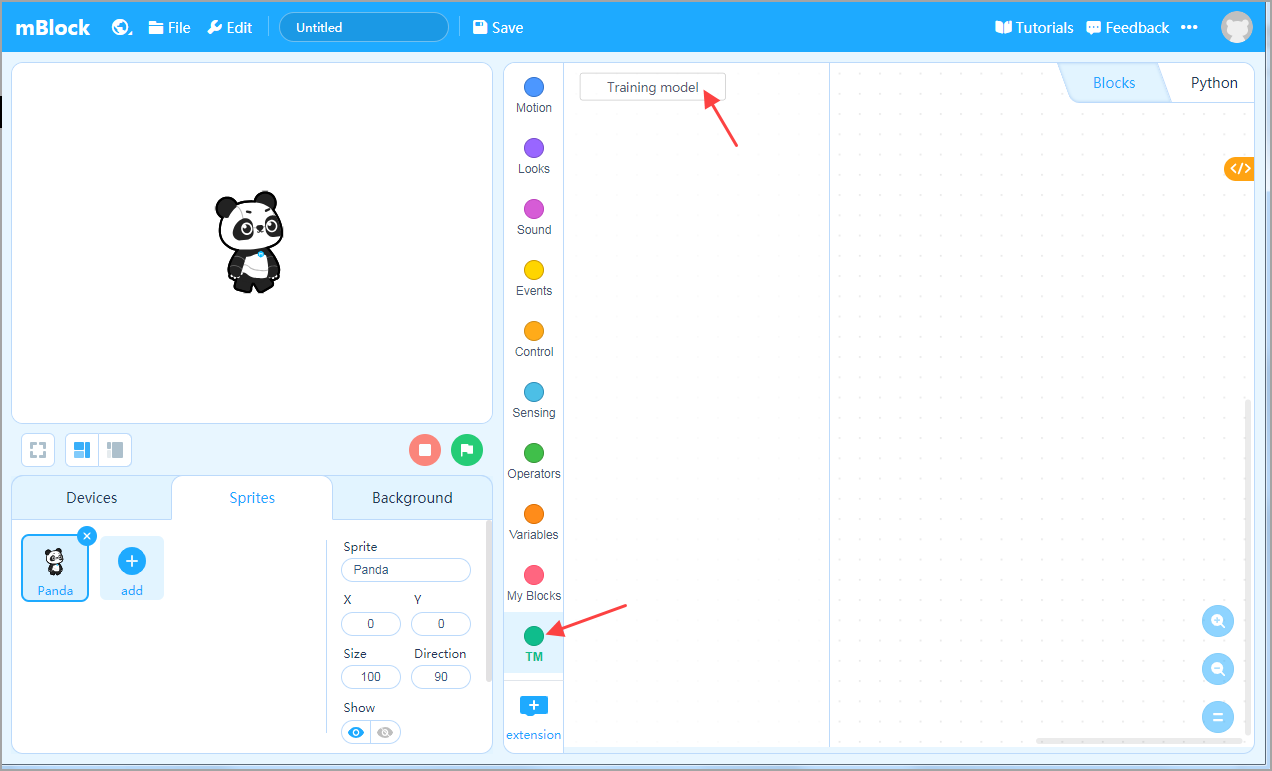
If your computer has multiple cameras, you can choose which one to use in the upper left corner of the screen.
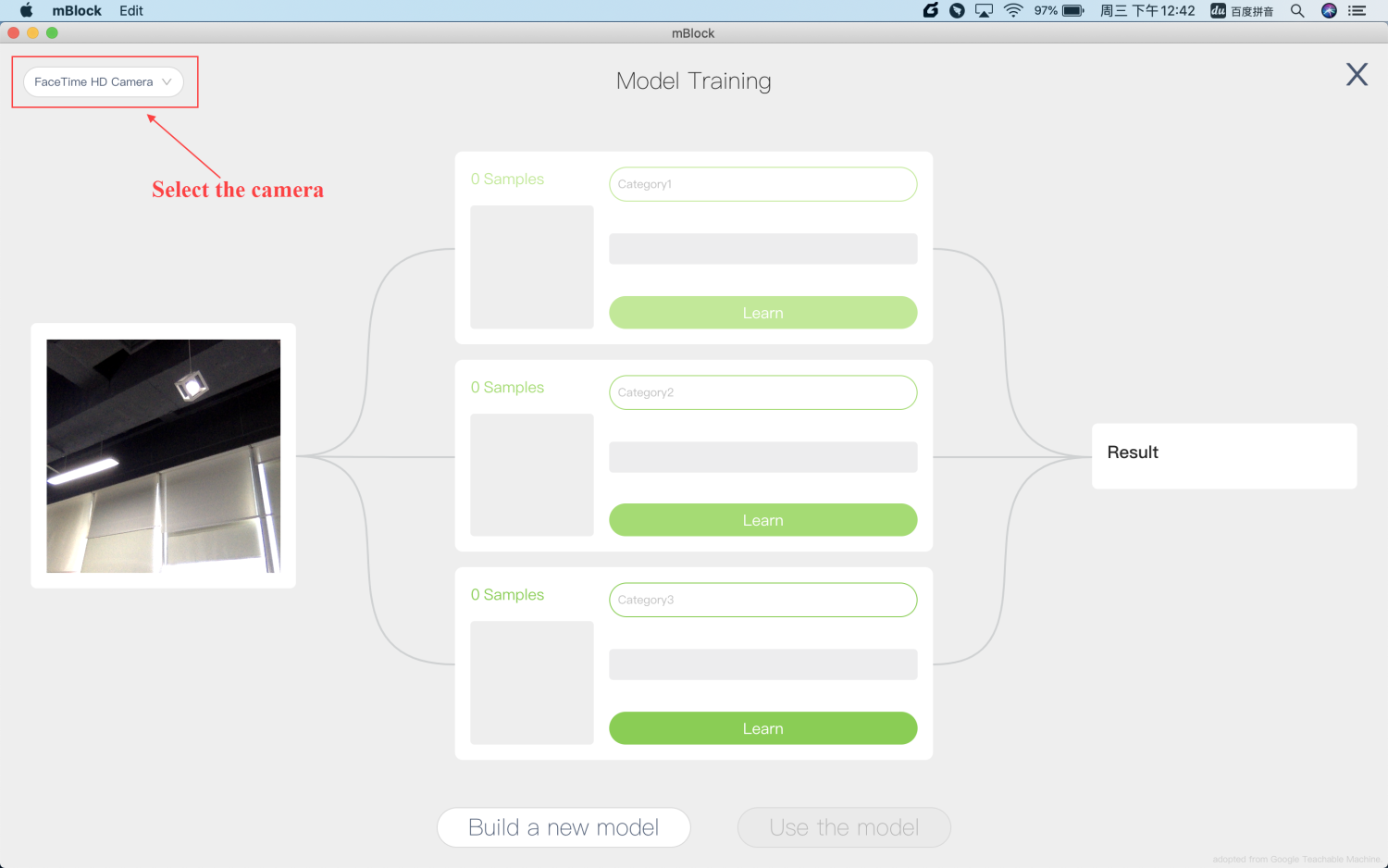
After selecting the camera, make a “Rock” motion with your hand, then hold down the Learn button on the first category item with the mouse to let the machine know what a “Rock” is. When the number of samples is more than 10, release the mouse to finish the learning.
Knowledge point: How does a machine learn what is “Rock” and what are “Scissors” ? It requires someone to provide some pictures to tell it, “This is the Rock, and these are scissors.” The pictures we take are called training samples, and the information in the samples that says “this is the rock” is called tagging. Many large companies hire people to do the tagging: Tell a computer all day that “This is the cat’s left eye.” As a result, large Internet companies such as Baidu or Google often take the lead in machine learning because people use their products every day, providing them with lots of training samples.
Knowledge point: The models we are going to create are called the supervised learning models. As the name suggests, the machine learns with the supervision of the labeled samples we provide. Another type of learning is called “unsupervised learning,” in which the computer sorts photos of some fruits without tagging information. The result is usually that “these photos belong to one category” and “those photos belong to another” .
Think about it: What are the uses of supervised learning? What are the uses of unsupervised learning?
In the same way, the machine is trained to recognize “Scissors” and “Paper”. Change the category names to Rock, Scissors, and Paper.
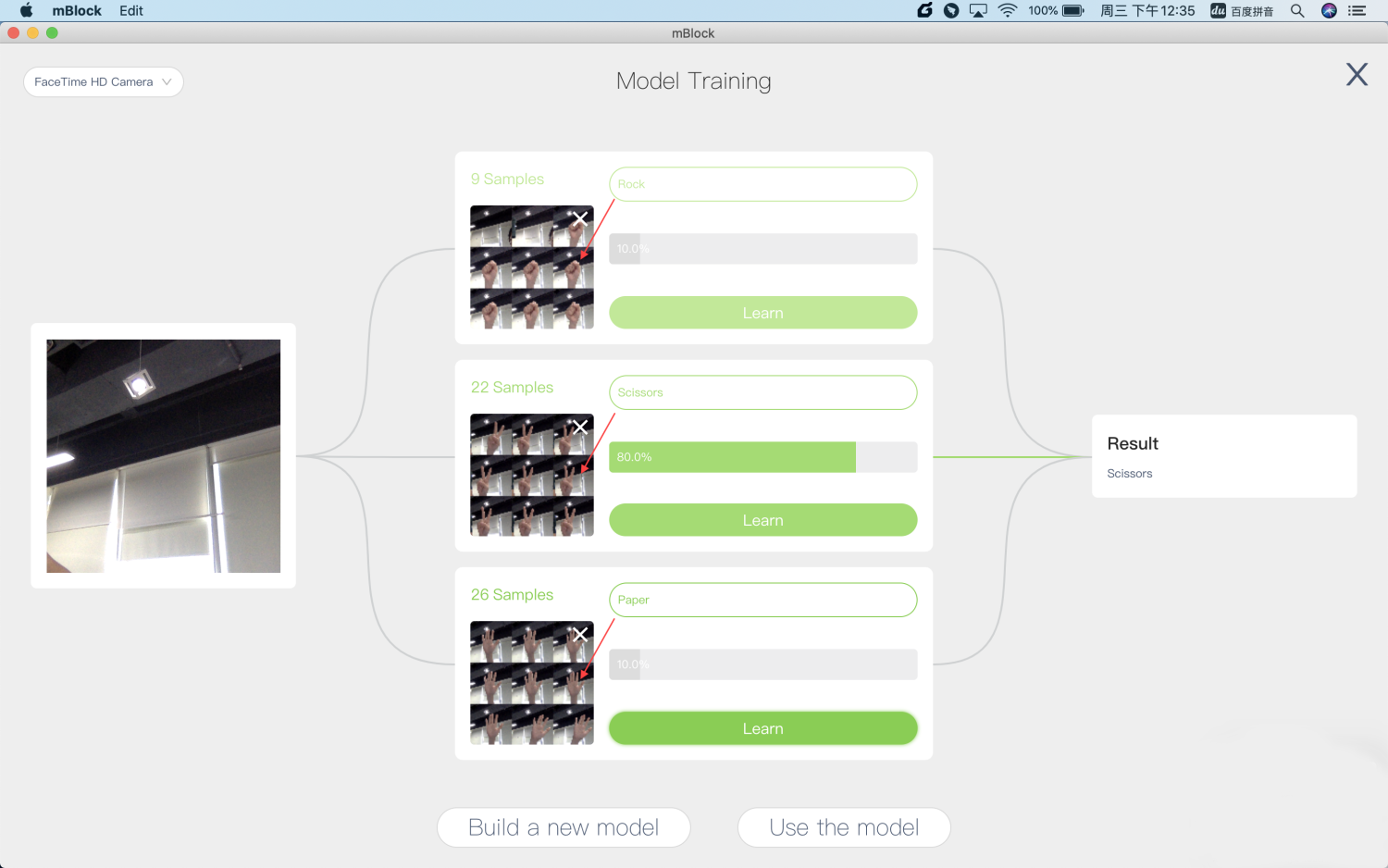
Then, switch between different gestures in front of the camera, and you can see that the percentage between each category keeps changing. It indicates the confidence the computer thinks the image it sees in each category is. The category with the most confidence is the classification result of the computer.

Knowledge point: What is “confidence” ? Confidence is the result calculated by the machine based on a new input after it is trained. It’s not a probability. Probability refers to the probability of a random event, where “confidence” has nothing to do with probability. It just helps the machine figure out what the result is.
Have a try: Try a few rock-paper-scissors motions, and try to get other students to do such moves, see if the computer can accurately judge the classification of movements? You can try it 30 times and write down on paper how many times the computer has got it right and how many times it has got it wrong. By dividing the number of attempts by the number of correct model judgments, we can determine the effectiveness of the models, which is also called the performance.
Think about it: Compare your models with other groups’. Whose model works better? Why? Can you try to improve your model’s performance? Is it better with more samples? Are there other ways to improve model performance?
Knowledge point: Underfitting and overfitting. If just a few samples are provided, the computer may fail to learn the characteristics of a thing, like the blind men touching an elephant, resulting in poor performance. This is called underfitting. On the contrary, overfitting refers to that the model overcharacterizes the given samples and fails to respond correctly to general situations. For example, it can recognize a person’s gesture at an angle as “scissors” but can’t see that the hand gesture of another person is also “scissors”. Overfitting is like some students who learn by rote, unable to apply what they have learned to a changing environment.
After the training is complete, click Use the model to write a program using the model on mBlock 5. You can click Build a new model to empty the current model and create a new model.
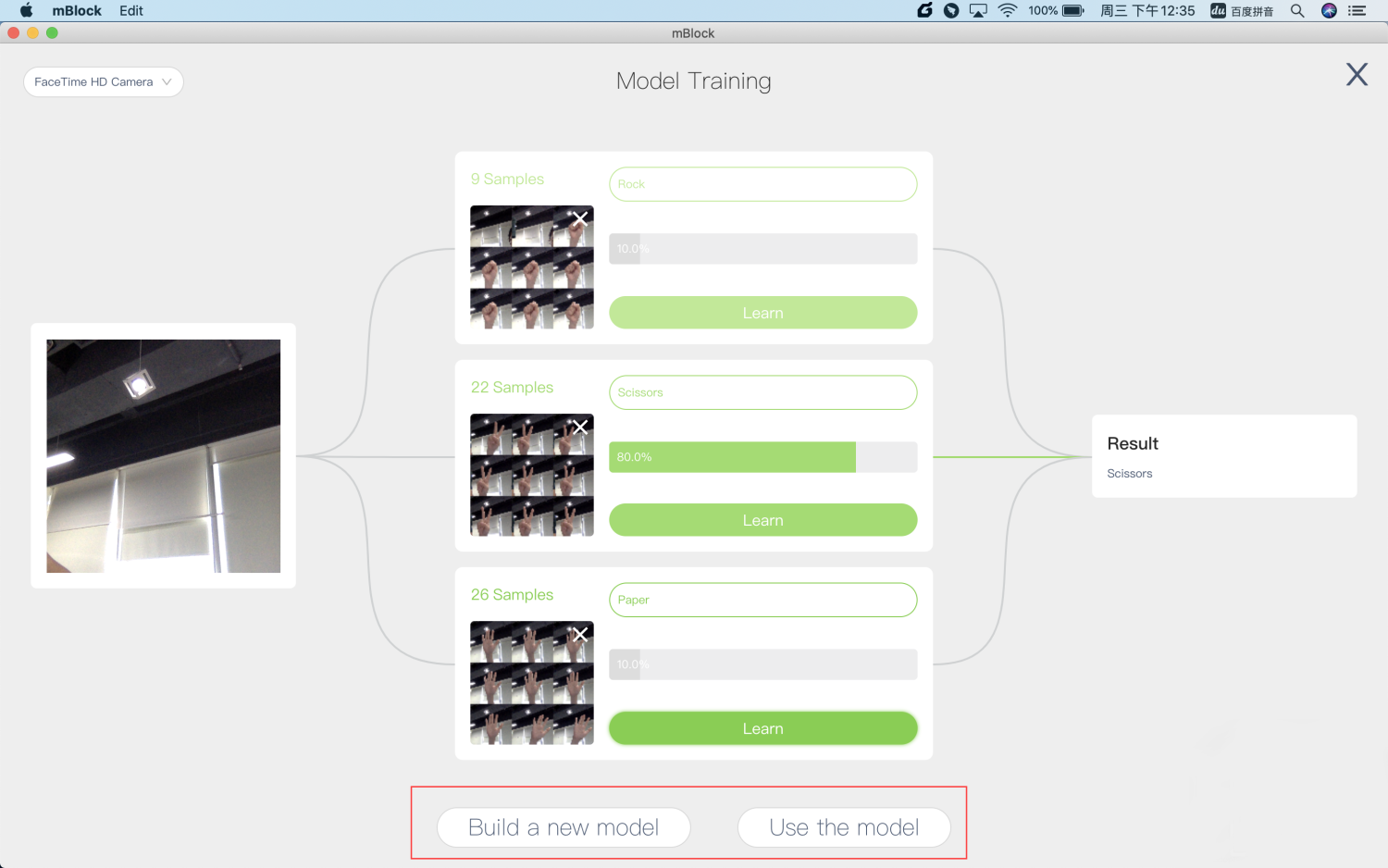
4. Use a created model on mBlock 5
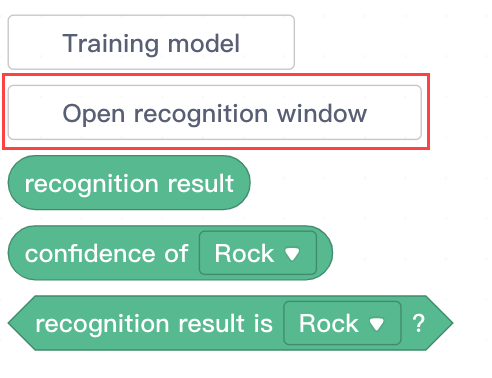
After using the model, three statement blocks have been added to the TM category: recognition result, confidence of ( ), and recognition result is ( )?
recognition result is the tagging of the object the computer thinks it sees. It’s a string, for example, Rock or Scissors.
confidence of ( ) is the confidence of the computer believes in a certain category. It’s a decimal number greater than 0 and less than 1, just like the percentage you see above. You can use it to make more specific judgments. For example, when the confidence for each category is less than a certain number, you can determine that the computer has not made a conclusion.
recognition result is ( )? is used to get a result of yes or no. You can place it in the “if” statement block as a condition for program execution.
Note: Before using a model, you need to click Open recognition window. The computer uses a created model only when the recognition window is open. Machine learning models are resource intensive. Turning them on may slow down the computer. Turn them on only when you need to use them.
Knowledge point: How do you make the models you have created work faster? A lot of people use graphics processing units (GPUs) for computing. Central processing units (CPUs) are often called the brain of computers. Unlike CPUs, GPUs are dedicated to graphics computing and are typically placed on a graphics card to make video games cool. What makes the game so cool is that it can quickly compute linear algebra (a college math subject). The speed at which linear algebra is computed determines the computing speed of position, angle, and light and shadow in 3D spaces (which determines how well the game is played). Similarly, machine learning uses a large amount of linear algebra computation, and therefore many people use GPUs (graphics cards) to speed up machine learning computation. Nowadays, some mobile phones made in China are using their self-developed chips for machine learning. In this way, their cameras can quickly identify the object being photographed and process the images to make them more beautiful.
Knowledge point: Training a model requires far more computing power than using a model. As a result, many people use many computers for group operation (which is called a computing cluster) or use supercomputers to train a model and then apply the model to microcomputers, such as mobile phone. The computing power of China’s Tianhe series of supercomputers is among the best in the world. Google “Tianhe-2” to learn more about them.
Now, it is time for block-based coding. Think about how you can use this model. Here’s a simple (but boring) example. Try to make it more interesting.
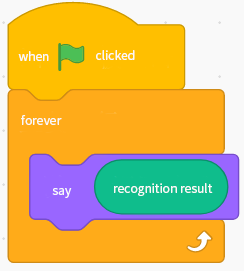
Have a try: Use other blocks of mBlock 5 in combination with the TM blocks to see what you can create. If you are confident, you can compile a program to enable the computer to fight with you in the rock-paper-scissors game. You can also think about what else you can teach a computer to recognize.
Think about it: Besides license plate recognition, what else can we use machine learning to do?
Knowledge point: Visual models created on mBlock 5 for machine learning use a technique called Convolutional Neural Network (CNN, adapted from Google’s Teachable Machine). It allows areas of an image to be abstracted to a higher level. CNN has made neural networks and machine learning hot again (the concept of neural networks first appeared in 1943) with excellent performance. It also allows mBlock 5 to achieve high machine learning performance with a small sample size (a dozen to dozens).